
Authors:
(1) Michal K. Grzeszczyk, Sano Centre for Computational Medicine, Cracow, Poland and Warsaw University of Technology, Warsaw, Poland;
(2) M.Sc.; Paulina Adamczyk, Sano Centre for Computational Medicine, Cracow, Poland and AGH University of Science and Technology, Cracow, Poland;
(3) B.Sc.; Sylwia Marek, Sano Centre for Computational Medicine, Cracow, Poland and AGH University of Science and Technology, Cracow, Poland;
(4) B.Sc.; Ryszard Pręcikowski, Sano Centre for Computational Medicine, Cracow, Poland and AGH University of Science and Technology, Cracow, Poland;
(5) B.Sc.; Maciej Kuś, Sano Centre for Computational Medicine, Cracow, Poland and AGH University of Science and Technology, Cracow, Poland;
(6) B.Sc.; M. Patrycja Lelujko, Sano Centre for Computational Medicine, Cracow, Poland;
(7) B.Sc.; Rosmary Blanco, Sano Centre for Computational Medicine, Cracow, Poland;
(8) M.Sc.; Tomasz Trzciński, Warsaw University of Technology, Warsaw, Poland, IDEAS NCBR, Warsaw, Poland andTooploox, Wroclaw, Poland;
(9) D.Sc.; Arkadiusz Sitek, Massachusetts General Hospital, Harvard Medical School, Boston, MA, USA;
(10) PhD; Maciej Malawski, Sano Centre for Computational Medicine, Cracow, Poland and AGH University of Science and Technology, Cracow, Poland;
(11) D.Sc.; Aneta Lisowska, Sano Centre for Computational Medicine, Cracow, Poland and Poznań University of Technology, Poznań, Poland;
(12) EngD.
Table of Links
Conclusion, Acknowledgment, and References
Methods
To compare cognitive effort exert by gamified and non-gamified mobile surveys we: collected two datasets that will be used for the development of a cognitive load detector and evaluation of gamified survey app. The experimental flow is presented in Figure 1. In this section, we describe the development of cognitive load detector utilising raw PPG signal. We selected gamification features and implemented gamified and non-gamified mobile survey applications. Lastly, we applied the cognitive load detector to PPG signal captured during responding to gamified and non-gamified mobile surveys.
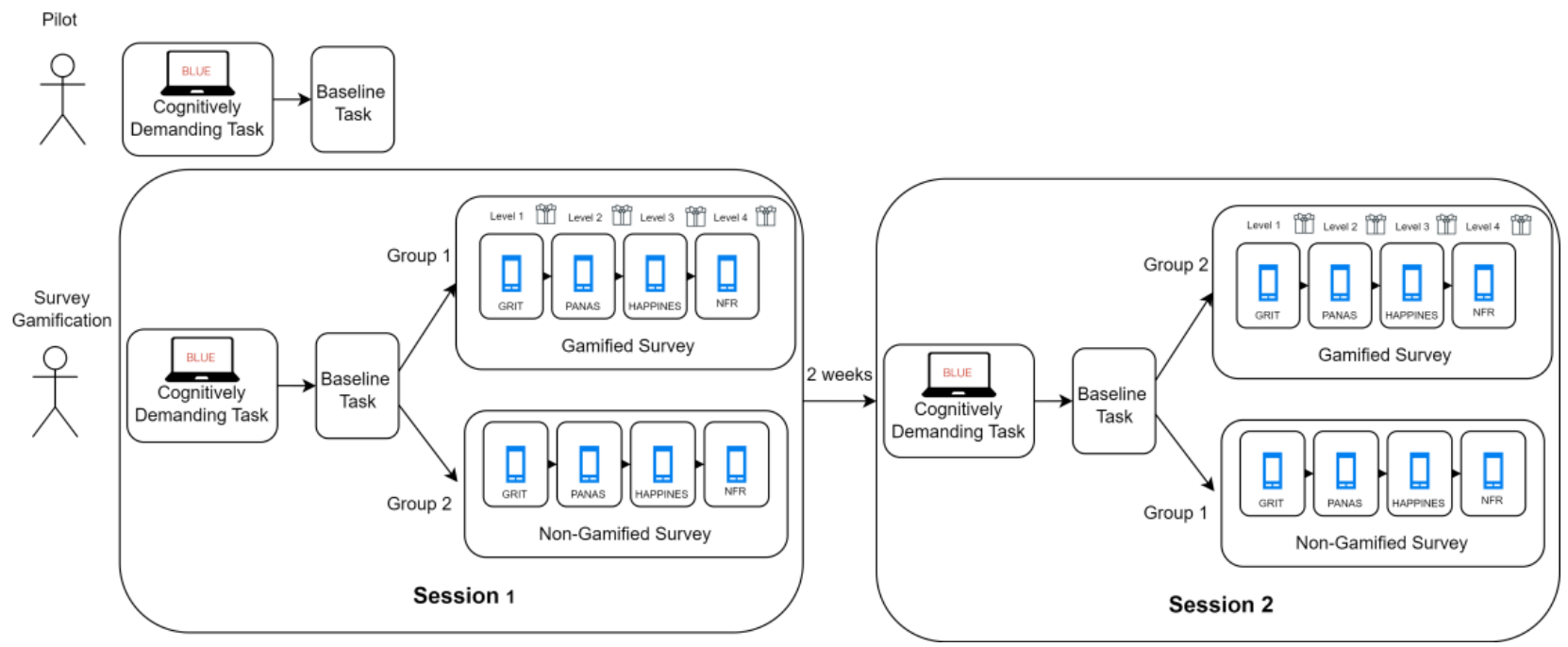
Data Collection. The study was part of a larger well-being at-work study and was advertised through internal company email and Slack channels. We collected data from 24 healthy participants. Data from 11 participants were used for cognitive load model development and the remaining data have been used for evaluation of survey gamification. Participants performed all tasks in the seated position. The cognitively demanding task was conducted on the PC, while surveys were being completed on the provided smartphone.
Pilot Dataset. To develop a cognitive load detector we gathered a pilot dataset capturing the physiological signal from 11 volunteers (5 females, 6 males aged 21-45) in two experimental conditions: cognitive load and baseline. In cognitive load condition, participants performed a Stroop test8, a cognitively demanding task in which participants are asked to promptly indicate colour of the text, but the text states the name of the colour that does not match the colour of the text, e.g. the word "red" printed in green instead of red ink. The Stroop task had 120 trials and we used PsyToolkit[17],[18] implementation of the test. In the baseline neutral condition, participants were asked to sit and not perform any task. For the initial participants, the baseline condition lasted just a minute but later it has been adjusted to 3 minutes to match the average time needed to complete the Stroop test. In both conditions, participants wore Empatica4 device, on the wrist of their non-dominant hand, which recorded Blood Volume Pulse (BVP) (64 Hz), Electrodermal Activity (4 Hz), Temperature (4Hz), and Acceleration (32 Hz). For the purpose of further experiments, we used only BVP which can be captured by consumer-grade smartwatches.
Survey Gamification Dataset. To evaluate the impact of gamification on participants' cognitive load, we captured signal from 14 volunteers who first performed the same two tasks as in the pilot study and then completed either gamified or non-gamified survey. Each participant was planned to perform the experiment twice with a two weeks break between experimental sessions as a part of the work well-being study. To control for task familiarity, we divided the participants into two groups: the first group filled the gamified surveys in the first session and the non-gamified surveys in the second session, the second group had the opposite order. The participants were not informed that there will be a difference in the mobile survey application between sessions.
To facilitate the replication of our findings the pilot and survey gamification dataset has been made publicly available[6] on PhysioNet[5]. The study was approved by the AGH University of Science and Technology Ethics Committee. Note that one participant did not agree to make their data publicly available and two participants did not complete the second session. Therefore, in this work, we report only on results from 11 volunteers from the survey gamification experiment who participated in both conditions gamified and not (7 females and 4 males, age 26-55). There are 5 volunteers who filled gamified surveys in the first session and non-gamified in the second session and 6 volunteers who started from a non-gamified survey.
Cognitive Load Detector. Our model is a shallow 1D CNN, used previously for PPG signal classification in cognitive load detection[11] and stress classification tasks[7]. The model consists of 2 convolutional layers with 16 and 8 filters respectively and a kernel size of 3, followed by a max pooling layer and fully connected layer with 30 nodes and an output layer of size 2, corresponding to two target prediction classes: cognitive load or neutral. The model was implemented in Keras with the Tensorflow backend. We have not performed extensive parameter search concerning the number of layers nodes and kernel sizes but kept the parameters as reported in previous works[8],[10].
Training and Validation Protocol. We experimented with two training protocols: 1) Vanilla- training only on captured pilot cognitive load dataset and 2) WESAD pre-training followed by tuning on pilot dataset.
Vanilla. We train the models with Adam optimiser and early stopping on validation data loss, the learning rate of 0.001 and patience of 10 epochs. Given the limited amount of data, we adopt Leave-one-out (LOO) approach to model evaluation. In this setting, the model is always tested on data from one subject and trained and validated on data from remaining subjects. We use 8 subjects for training and 2 for validation. The training examples are extracted using a varying window size of length 10, 30 or 60 seconds (depending on experimental conditions) and step size of 8 samples in cognitive load and 4 samples in baseline condition to correct for dataset imbalance. The validation and test datasets have the same window size as the training set but validation data were extracted with a step size of 32 samples (half a second) for both cognitive load and baseline and the test was extracted with a step size of 64 samples corresponding to 1 second. We use weighted F1-score as a performance metric.
WESAD Pretraining: To estimate to what extent 1D CNN model pre-training can facilitate cognitive load detection we utilise publicly available WESAD dataset[16]. The dataset captures signals from 15 volunteers in stressed, amused and baseline conditions. We selected this dataset because it has been also gathered with the use of Empatica4 device and therefore the required information transfer can be limited to population and task, not the device. We trained the model on 13 subjects from WESAD dataset and validated on 1 and test on 1 subject. The model was trained to classify stressed vs non-stressed (baseline or amused) physiological state. In this two-class problem, the step size was 18 samples for non-stress condition and 12 samples for stress condition. This yields for example around 117000 training examples when the window size is 60 seconds. The signal window size corresponded to the widow size used for cognitive load classification. The pre-training was performed with a default learning rate of Adam optimiser (0.001) in Keras. During fine-tuning for cognitive load detection the models were trained with a lowered learning rate of 0.0001.
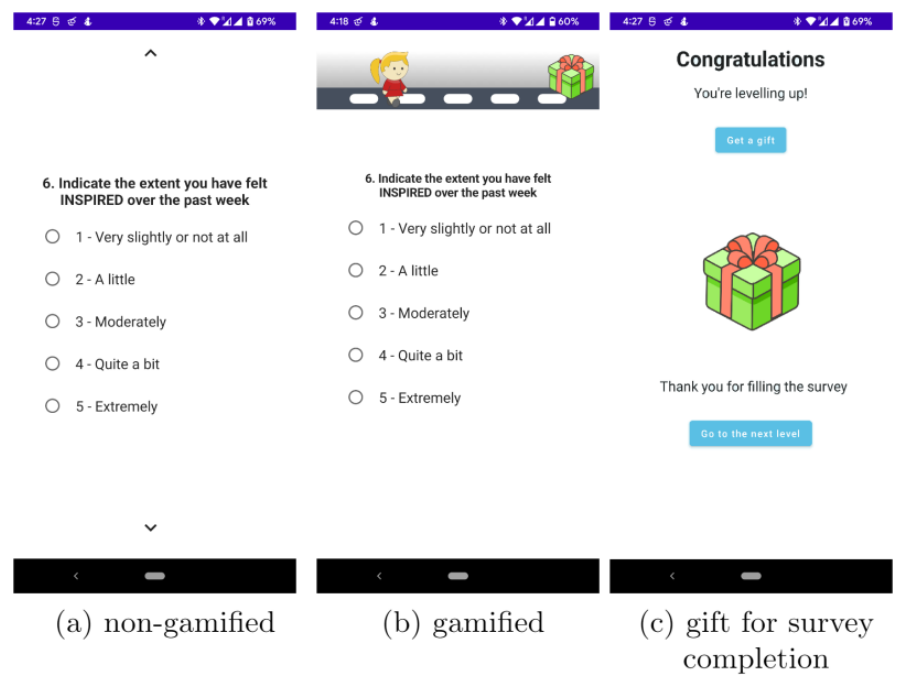
Application Development. We developed two versions of the mobile survey application, both were written in Kotlin and utilized Jetpack Compose package. The survey application consisted of four surveys: GRIT, Positive and Negative Affect Schedule (PANAS), HAPPINES and Need for Recovery (NFR) relating to mental well-being in a work context. In the standard survey application, participants were shown one question at a time (see Figure 2a) and after the completion of all questions from one survey, they proceeded to the next questionnaire. In gamified survey condition, we added a progress-tracking element in the form of a personalized avatar that walks towards a present (see Figure 2b). Our previous research showed that the majority of participants in our study fall into the Player gamer archetype, therefore, we selected game elements associated with this role (progress tracking, points, rewards and levels). The game task is to complete all four surveys. Each filled survey is associated with leveling up. After completion of each level, the participants see a congratulation screen in which they receive a present and points as a reward (see Figure 2c). Game elements personalization was only achieved through tailoring of the avatar.
This paper is available on arxiv under CC BY 4.0 DEED license.